Snowflake 的改进与实现
Snowflake 算法是Twitter提出的一种分布式ID生成算法。它满足了一个ID生成器所需的几大要素:1、全局唯一;2、趋势递增;3、可反解。这样的ID生成器在分布式系统中十分有用。SnowFlake 原生算法由以下几个部分组成:
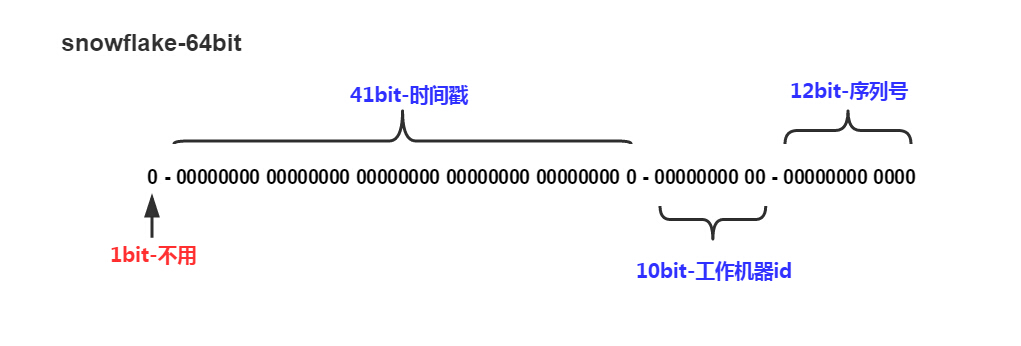
Snowflake 高位使用以毫秒为单位的时间戳,后12位使用递增数字。每毫秒可以生成 2^11 = 2048 (存在一个符号位) 个ID,每秒即可生成2048000个ID。
Snowflake这样依赖时间的ID生成算法注定存在一个问题:时间的准确度问题。这一算法有一个默认前提:分布式环境下时间获取总是准确的,即时间总是递增的。而现实环境中,这样的条件很难满足。总会因为硬件、软件、人的原因造成时间变化。如果你的硬件时间本身就比正常时间快,而你接入了一个NTP服务,每当进行NTP时间校准时,你的机器时间总会向后回拨一段时间,这时悲剧就来了:有极大可能性生成重复ID。因为每过1ms我们就会把前1ms的序列丢弃,时钟回拨后您的序列需要从0开始算起,于是就出现了重复ID。
另外,如果您在Github上进行Snowflake搜索,很有可能会看到这样一段代码看到44行了吗?那把硕大无比的排他锁一直锁到了59行。这…太不优雅了。
针对上面提到的两个问题,我进行了如下改进:
1、时间戳由毫秒变为秒
2、使用环形列表对时间戳对应的序列进行缓存
3、使用CAS操作避免大粒度悲观锁
为了 缓解 时钟回拨问题,我需要对之前的序列进行缓存,而原生算法很显然是不利于缓存的,最坏的情况下每秒需要缓存1000个值,这显然对内存很不友好。于是我将时间戳改为秒为单位。同时可以把省出来的位交给序列。此时缓存一个小时的数据(即可以容忍一个小时的时钟回拨)也就只需要缓存3600个序列,完全可以接受。
环形列表:即整个列表的容量是一定的,当列表满了以后再加入的元素会按照入列的先后顺序覆盖之前的元素。
改进后的Snowflake生成的ID是这样组成的:
|–1位符号位–|--32位时间戳–|--21位序列–|--10位机器码–|
理论上每个节点每秒可以生成1048576个ID。
核心代码如下:
1 | public class CircleArray { |
所有需要进行线程同步的操作都使用了CAS操作,最大限度减小了锁消耗。最终,在我的本机16线程简单粗暴测试结果如下:
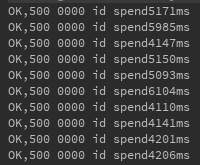
可见性能还是比较可观。
具体实现我已经放到了我的GitHub上,欢迎各位来翻牌子!
